In the Smile-project, we aim to migrate data processing approaches to serverless computing. In the course of the project, we asked what research and industry have done so far in this field. As a first approach to answering this question, we performed a multi-vocal literature review, based on this paper1. For the study, we defined two research questions:
Q1: What serverless data processing approaches exist in research and industry?
Q2: What use-cases and purposes for serverless data processing are currently investigated?
We started our search by searching the most common literature databases, namely ACM, IEEE, Springer Link, Elsevier, Google Scholar, Microsoft Academic, and our own Serverless Literature Database. After removing duplicates, the search yielded 245 papers. Out of these, we selected 76 relevant to our research question.
In these papers, we extracted 18 serverless data processing approaches. Out of those, ten made their source code available.
| Name | Source | Age 2 | Platform | Kind |
|---|---|---|---|---|
| PyWren | git | 679 | AWS3 | DTF4 |
| IBM PyWren | git | 11 | ICF5 | DTF |
| gg | git | 102 | AWS | DTF |
| Spark on Lambda | git | 429 | AWS | DTF |
| Marla | git | 723 | AWS | DTF |
| Ooso | git | 1156 | AWS | DTF |
| Wukong | git | 305 | AWS | DTF |
| Scar | git | 35 | AWS | P6 |
| Corral | git | 570 | AWS | DTF |
| Locus | git | 1362 | AWS | DTF |
What first catches the eye is the fact that almost all frameworks use AWS Lambda as their backend. Amazon being the first to launch a commercially available FaaS platform, could be a reason for this. Only IBM PyWren uses the IBM Cloud Functions as their backend for obvious reasons. We identified two kinds of tools supporting data processing: data transformation framework (DTF) and processing platforms (P). Data transformation frameworks enable data analysts to define jobs in terms of simplified interfaces. The DTF then managed part of the deployment and execution of each data transformation job. Notably, all DTFs share a similar approach to overcome challenges posed by the FaaS environment, such as intermediate data handling and intra-process communication by, for instance, using an intermediate cloud storage for these communications. Most offer a map or map-reduce abstraction to define transformation. In contrast, processing platforms are tackling these challenges with a more general approach. For example, SCAR offers a solution to deploy custom Docker containers on top of AWS Lambda and scale them faster than comparable Container-as-a-Service solutions. However, these processing platforms offer no specific tools for data transformation. Regardless of the type of framework, we noticed that the age of these frameworks varies a lot. One reason could be that most of these frameworks are not used actively outside of research purposes. Only some such as IBM PyWren, recently renamed to lithops, seems to be under very active development since 2018.
To answer the second research question, we extracted use cases from the relevant papers and categorized them to get an overview of the research directions.
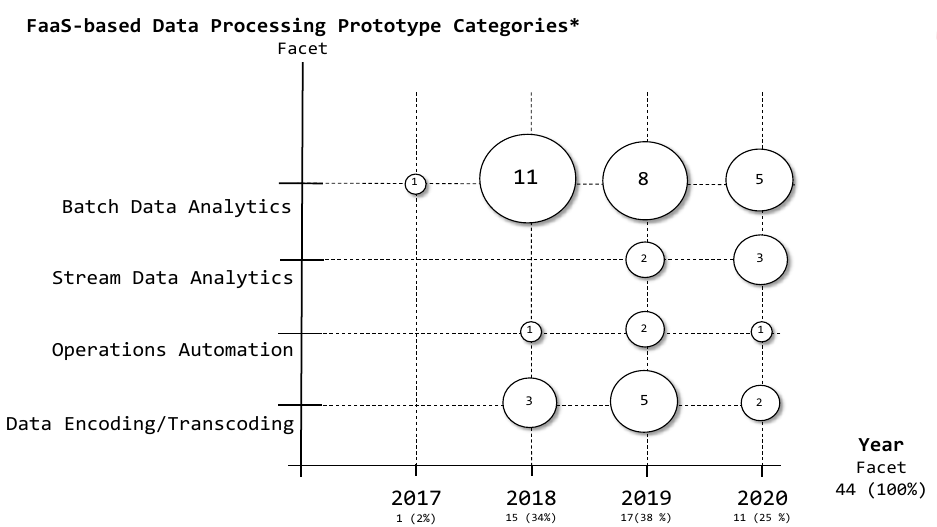
The most common use-case we found was batch data analytics a traditional field in data processing. Data encoding is the second most common use case often used for video encoding or image recogintion in videos. Stream Data Analytics is used for real time data analytics such as mobile device event streams. Operations Automation is a rather small field of reaasearch but interesting for huge distributed compiling and automatic incedence response.